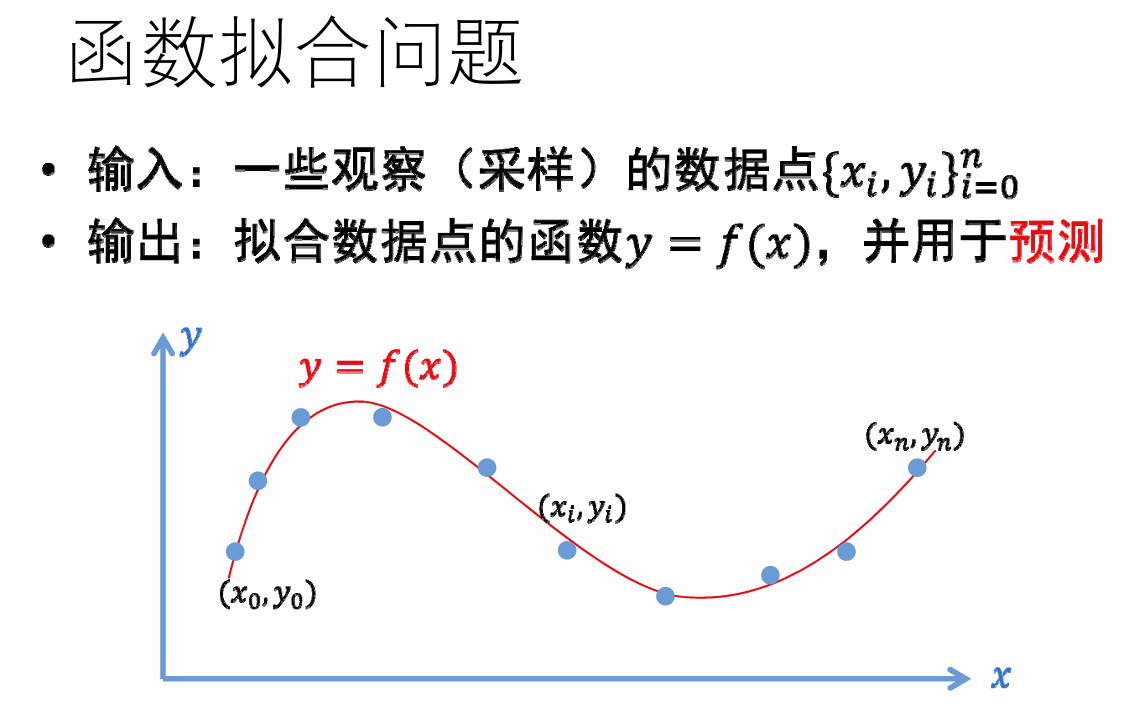
这是一篇点云处理综述,拖拖拉拉终于看完了。
基本信息
类型:综述
时间:2022
期刊:计算机系统应用
关键词:深度学习;目标检测;目标追踪;形状分类;点云分割
引用:王振燕, 孙红岩, & 孙晓鹏. (2023). 基于深度学习的大规模三维点云处理综述. 计算机系统应用, 32(2), 1–12. https://doi.org/10.15888/j.cnki.csa.008743
飞书文档链接:https://bp630wh8fk.feishu.cn/docx/YObYdRXXHorBvoxu2jecxDgRnyg?from=from_copylink
研究背景
论文背景
随着三维视觉的快速发展, 基于深度学习的大规模三维点云实时处理成为研究热点. 以三维空间分布无序
的大规模三维点云为背景, 综合分析介绍并对比深度学习实时处理三维视觉问题的最新进展,包含:
点云分割
形状分类
目标检测
测等方面算法的优势与不足, 给出详细的性能分析与优劣对比, 并对点云常用数据集进行简
要介绍, 并给出不同数据集的算法性能对比。
基础知识
三维点云数据通常包含几何位置信息、颜色信息和强度信息。其中, 颜色信息通过相机获取彩色影像, 再将其颜色信息赋予点云中对应的点;强度信息通过激光扫描仪接收装置采集到的回波强度。
基于深度学习的三维点云数据处理目前面临以下3个方面的挑战:
点云无序性及非结构性
点云旋转不变性
以及点云特征的有效提取
数据集和评价指标
数据集
点云分割常用数据集:ScanNet、S3DIS、SemanticKITTI
- 其中 ScanNet 和 S3DIS 均为室内场景: ScanNet 数据集共 1513 个场景数据、21 个对象类别, 其中 1201 个场景用于训练, 312 个场景用于测试; S3DIS 数据集由 3 个不同建筑的 5 个大型室内场景组成. SemanticKITTI 为室外场景, 包含市区、乡村和高速公路等场景的真实图像数据。
形状分类常用数据集:ModelNet
- 其中包含 127915个三维形状、662 类, 其子集 ModelNet10 包含 10 类4 899 个三维形状, ModelNet40 包含 40 类 12 311 个三维形状。
检测算法常用数据集:SemanticKITTI、Oxford、NYU
- Oxford 数据集由 21711 个训练子地图和 3030 个测试子地图组成. NYU 数据集包含超过 72k 个训练帧和 8k 个测试帧, 每帧包含 36 个带注释的关节。
算法性能对比:
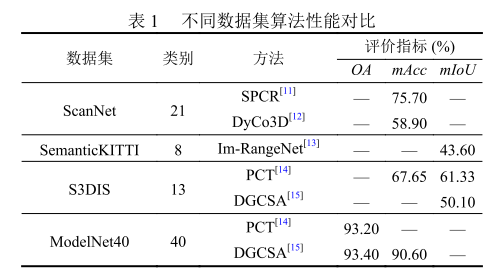
评价指标
常用的评价指标包括 mAcc、mIoU和 OA。
mAcc 是正类预测个数与所有预测样本数之比的均值,计算公式如下:
mIoU评估预测框与人工标记框的重合程度, 定义为:
OA 是在预测为真的样例中、被正确预测为真的比例,计算公式如下:
召回率 (recall, R) 是所有正样本样例中, 被正确预测为真的比例, 定义为:
精度-召回率 (precision-recall, PR) 曲线的横坐标是召回率, 纵坐标是 OA。若在 R 增长的同时, OA 在高
水平范围变化不大, 则说明分类器的性能较好。
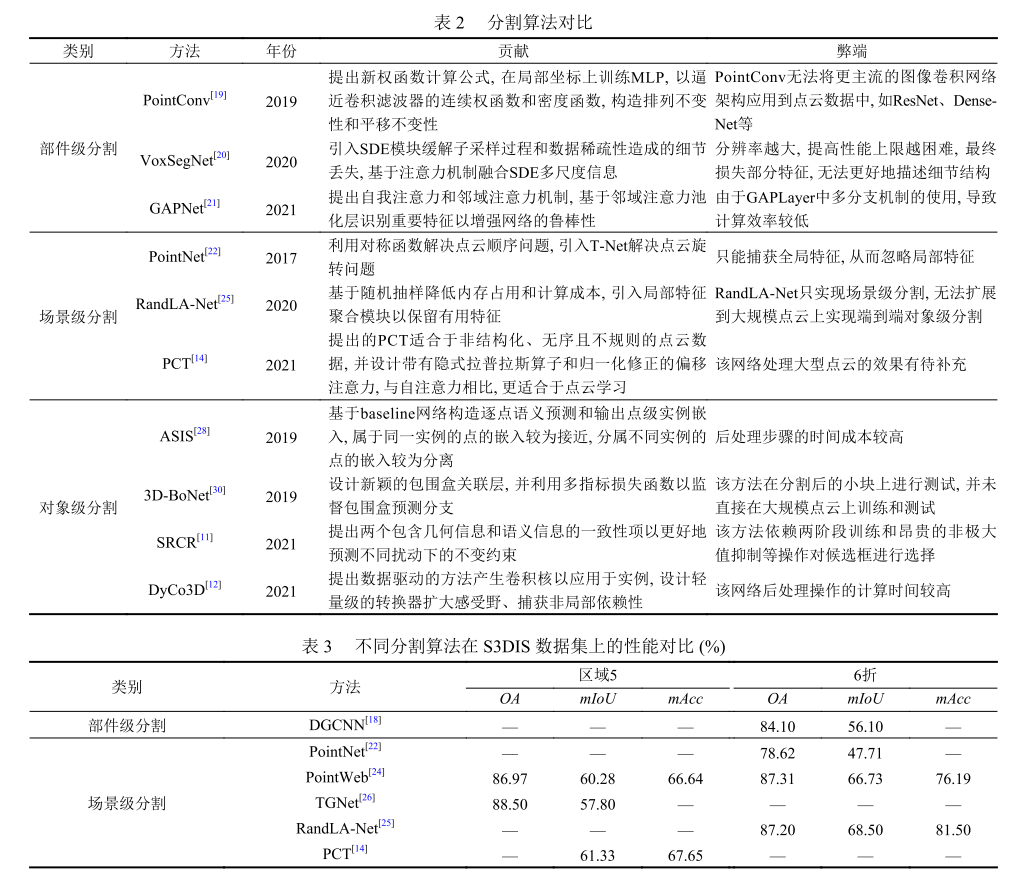
点云分割方法
点云分割指将整个点云聚类为多部分点云, 每部分点云对应独立的物体对象, 分为部件级分割、场景级分割和对象级分割。
部件级分割

场景级分割

对象级分割

在部件级分割算法中,VoxSegNet 从体素化三维编码信息提取特征, 并基于体素化形状提取多尺度特征, 但会导致部分信息丢失;而 SO-Net、DGCNN、PointConv、GAPNet 重点解决直接处理点云数据, 用于探索局部上下文信息和注意力机制的学习架构, 提高了算法精度, 但速度较慢. 在场景级分割算法中, PointNet、PointNet++、RandLA-Net 以共享 MLP 为网络基本单元, 利用累积跳跃连接增强语义信息, 效率相对较高; TGNet 解决了由输入与邻近坐标或特征间的高几何相关性导致分割性能欠佳的问题, 并克服了传统聚集函数丢弃或忽略局部邻域间的结构联系; 而 PCT 借助 Transformer 的优势, 并结合注意力机制学习特征, 具有良好的语义特征学习能力, 在计算效率、内存占用等方面远优于上述算法. 在对象级分割算法中, SGPN、ASIS、JSIS3D、DyCo3D将实例分割看作语义分割的后续聚类步骤, 为每个点学习鉴别嵌入特征, 再通过均值偏移等聚类算法将同一实例点聚集到一起, 但其目标性较差, 且后处理步骤的时间成本较高; 而 SRCR 主要研究将实例分割问题转化为三维目标检测和实例掩码预测 2 个子任务, 这通常依赖两阶段的训练和昂贵的非极大值抑制等操作对密集候选框进行选择; 3D-BoNet 主要研究单阶段、无锚且端到端的包围盒回归算法, 通过显示预测目标包围盒, 得到的实例有更好的目标性, 且不需要复杂耗时的区域候选框网络和后处理步骤。
形状分类方法
点云分类是为每个点或组分配语义标签的过程。
基于卷积的方法
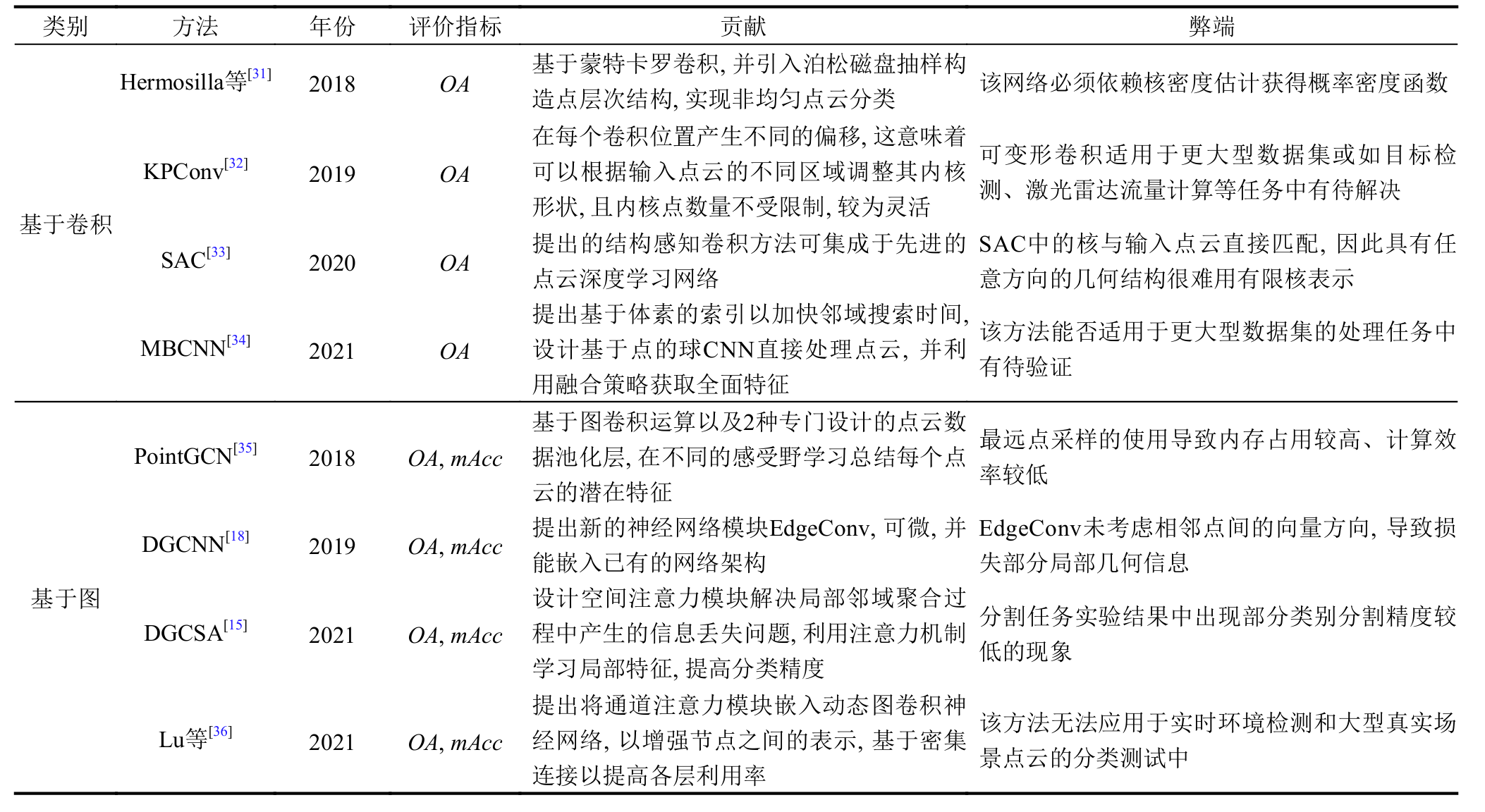
在基于卷积的方法中, Hermosilla、KPConv、 SAC主要研究在连续空间定义卷积核, Hermosilla等将卷积当做蒙特卡罗估计的过程, 并使用泊松磁盘抽样构建点云。KPConv利用相关性函数计算出每个矩阵的系数, 在此基础上, 核函数对所有矩阵加权求和得到权重矩阵实现特征的更新, SAC将卷积核看作由三维点构成的几何模板; MBCNN是在规则网格上定义卷积核, 利用共享参数的过滤器(kernel), 通过计算中心像素点与相邻像素点的加权和以构成特征映射实现 征的提取。在基于图的方法中, PointGCN将卷积定义为频谱滤波, 借助图谱的理论实现拓扑图上的卷积操作, 在训练阶段, 将输入信号转换为潜在特征映射的图滤波器系数以区分对象类, 利用重新缩放的拉普拉斯算子以提高网络的稳定性和性能; 而DGCNN、DGCSA、 Lu等直接在每个结点的连接关系上定义卷积操作, 类似于传统的卷积神经网络中的卷积, 可直接在图像的像素点上进行卷积, DGCSA与Lu等均结合DGCNN 的优势进行改进, 在计算效率与精度方面均优于DGCNN。
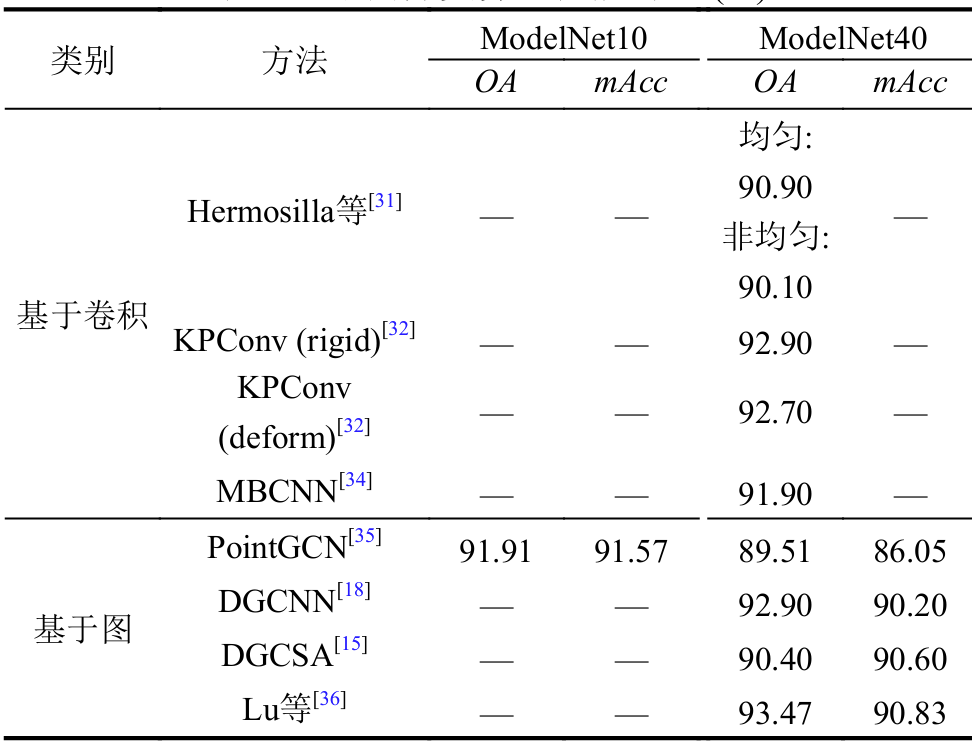
形状分类算法的性能比较如表所示, 比较内容包括类别、方法、总体精度、均值精度. 通过对比, Lu等的总体精度和均值精度都明显高于其他分类算法, 主要原因在于利用DGCNN的优势并结合密集连接提高网络性能; KPConv可根据输入点云的不同区域调整其内核形状, 且内核点数量不受限制, 在总体精度方面优于其他基于卷积的方法和部分基于图的方法。综合分析, 基于卷积的网络可以在非均匀三维点云上实现优异的性能。
目标检测
基于多视图的方法
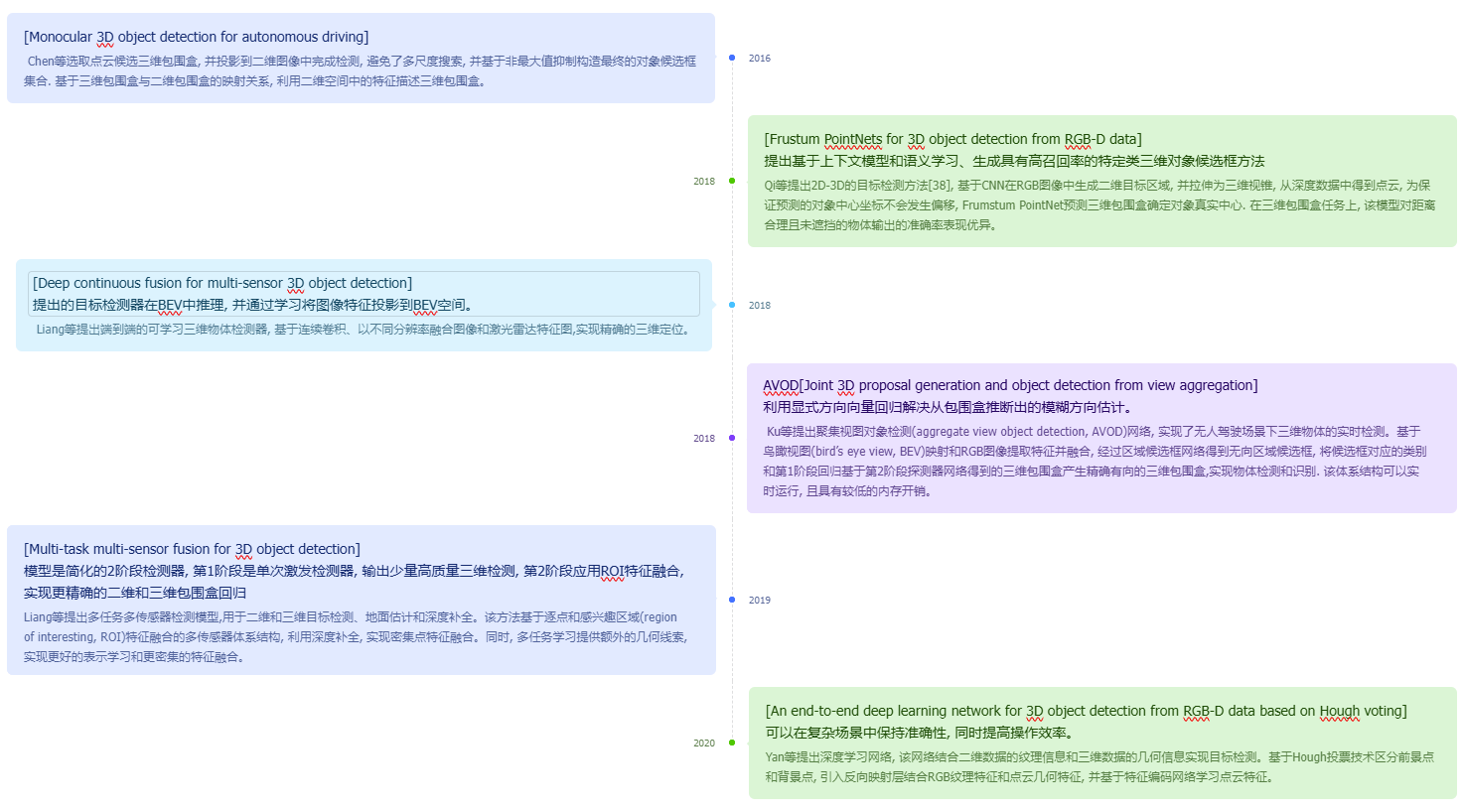
基于多视图的方法将三维对象投影到多个视图中提取相应视图特征, 再将其融合。
基于体素的方法
基于体素的方法实质是点云体素化后利用二维或三维卷积实现目标检测。
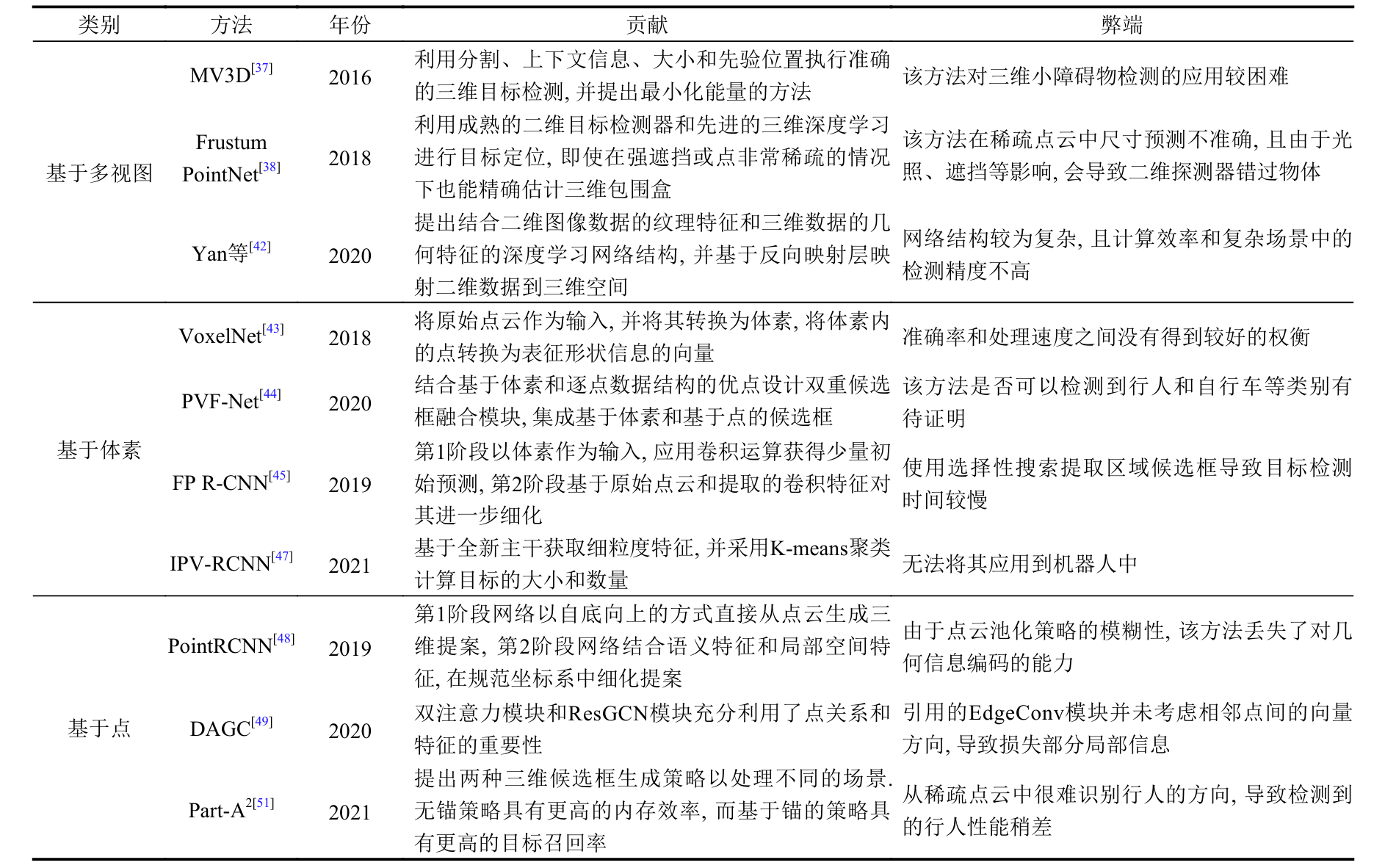
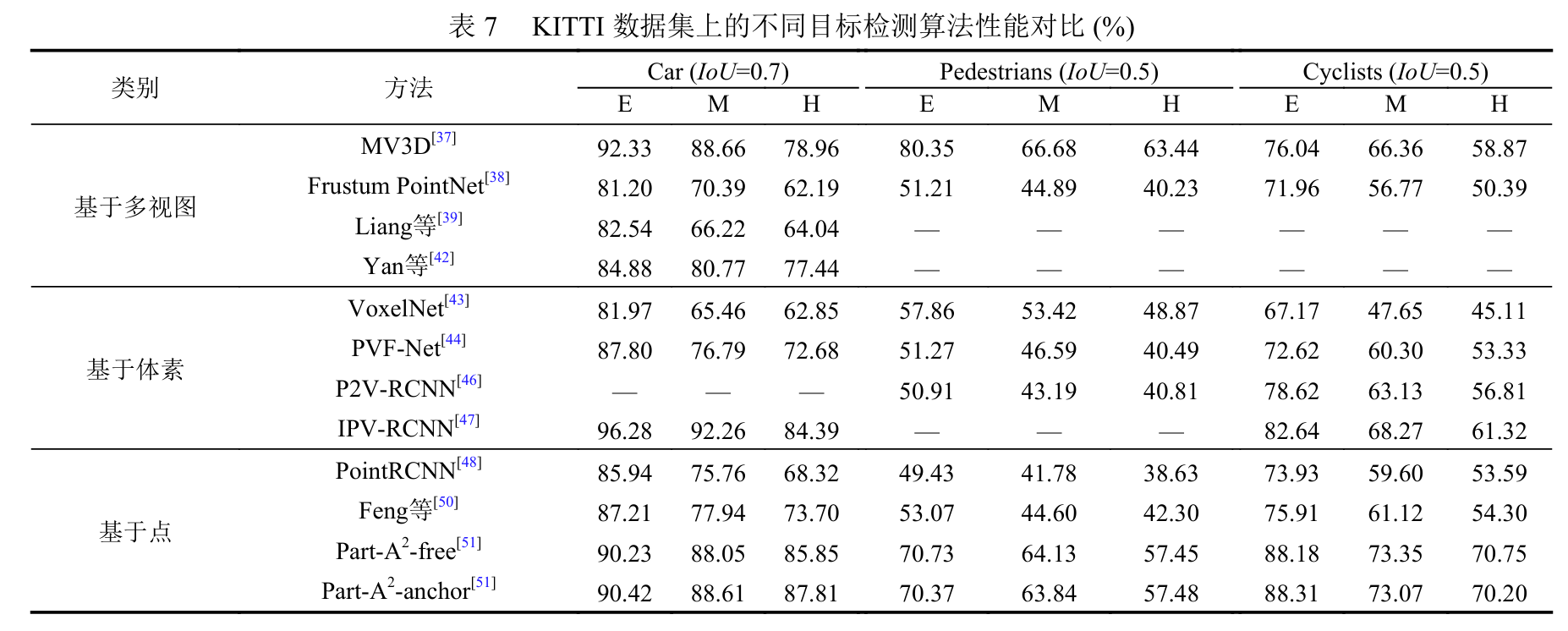
基于多视图的方法中, MV3D和Frustum PointNet主要解决2D-3D目标检测问题, 但均非常依赖于从第1步生成的二维检测结果, 其中, MV3D在小目标物体检测上表现不佳, 为解决此问题, AVOD在特征提取阶段融合浅层和深层特征, 产生高分辨率特征映射, 并缩小参数维度; Liang等和MMS重点学习跨模态特征表示, 实现不同模式(图像与激光雷达点云)的信息融合; 为解决由摄像头传感器受光线影响丢失深度信息的问题, Yan等设计反向映射层和聚集层将二维纹理信息与三维几何信息结合, 以获取更多有用信息. 在基于体素的方法中, VoxelNet提出单阶段检测法, 虽然可以学习具有各种几何形状的物体的有效区分表示, 并取得较好结果, 但它需要权衡准确率与处理速度; 为解决体素化造成的部分信息丢失的问题, PVF-Net充分利用体素密集结构(voxel dense structure, VDS)和点稀疏结构(point sparse structure, PSS)的优势, 并在两种结构之间进行折衷; 针对RCNN出现的训练时间慢、步骤复杂、内存占用高等问题, FP R-CNN、P2V-RCNN、 IPV-RCNN均提出改进两阶段目标检测算法. 在基于点的方法中, 由于点云池化策略的模糊性(不同的对象可能最终汇集到同一组点), PointRCNN会丢失对几何信息编码的能力; 为解决此问题, Part-A2提出可区分感兴趣区域的点云池化操作以消除模糊性; DAGC和 Feng等均提出两个新的模块以提高类别精度。
通过对比, IPV-RCNN的类别精度明显高于其他基于体素、基于多视图的方法和基于点的方法, 主要原因在于提出的在线数据处理方法提高了训练效率, 并降低计算复杂度. 综合分析, 基于点的方法的类别精度均达到了较高水平且相对稳定, 主要是因为体素化和多视图方法会造成部分重要信息丢失, 三维CNN的存储和计算效率都很低, 而基于点的方法直接处理点云, 避免了有用信息丢失的问题。
结论
文章分析比较了深度学习在处理大规模三维点云的点云分割、形状分类、目标检测等3个方 面的研究进展, 以及常用的数据集和相关评价指标。认为基于深度学习算法的大规模三维点云处理今后的发展趋势包含:
点云分割
目前算法通过点云分块、对象部分之间上下文关系等策略处理点云导致计算复杂度高、内存占用较大, 因此实现直接处理百万级的大规模点云是今后的重要研究课题。
可能思路:结合超点图、给出与点-体素联合等降低计算复杂度和内存占用;结合RandLA-Net基于随机抽样法降低 空间复杂度、给出Transformer等思路,提高计算效率。
形状分类
局部特征直接影响算法精度, PointNet无法捕获局部特征导致精度不高、DGCNN虽然解决了此问题, 但由于EdgeConv未考虑相邻点间的向量方向, 依然损失了部分局部特征, 直接影响算法精度。
可能思路:基于邻域查询机制、融合二维图像特征的三维局部几何特征将有助于提高算法精度。
目标检测
信息融合: 二维RGB图像中蕴含丰富的深度信息, 而点云数据具有独特的几何信息, 将图像与点云数据中的信息融合, 可以让网络学习到更多有用特征. 所以, 目标检测性能更好, 可以考虑结合AVOD算法提 取图像特征、MMS算法学习图像与点间的信息融合等思路实现.
数据稀疏问题: 由于近程雷达点云传感器在扫描远距离目标或遮挡目标时, 采集的数据非常稀疏, 从而影响检测算法, 如Frumstum PointNet对遮挡目标的输出准确率较低、Part-A2从稀疏点云中很难辨别出行人的方向。因此, 可以考虑结合IPV-RCNN中基于数据增强的训练方法与AVOD算法实现检测精度和准确率的提高。