今天的主题是我在组会时分享的一篇论文,本着尽量把学习过程记录下来的想法,后续应该还会有这类博客。第一次写这类论文笔记可能会略显粗糙,但就先这样吧。
这是CVPR 2021的一篇研究点云配准方法的论文,叫《PREDATOR: Registration of 3D Point Clouds with Low Overlap》。
论文地址:[2011.13005] PREDATOR: Registration of 3D Point Clouds with Low Overlap (arxiv.org)
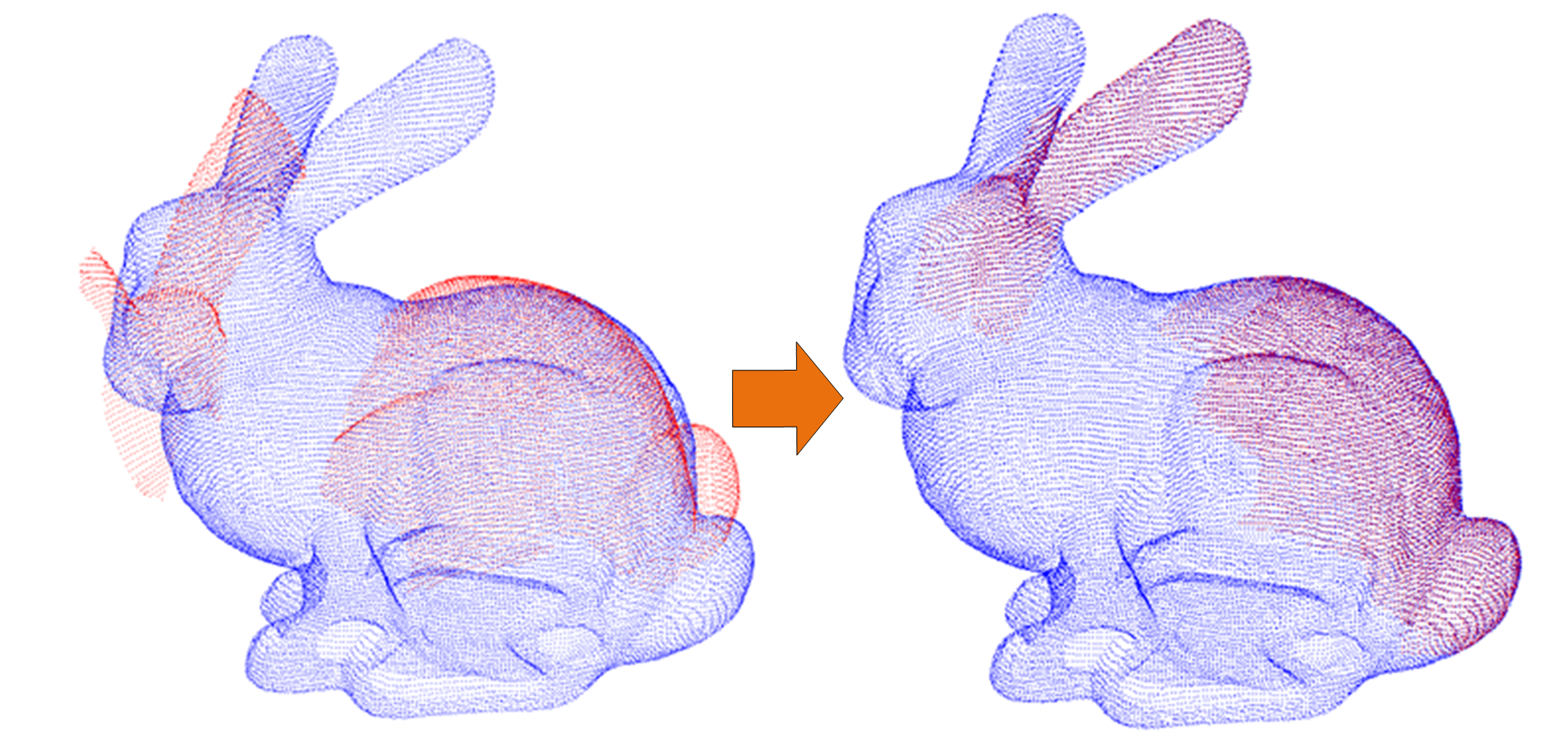
文章提出了一种针对低重叠区域情况下的点云配准模型PREDATOR,是一种基于学习的点云配准方法。有关点云配准的基本知识可以看上一篇博客。
基于学习的点云配准方法
基于学习的点云配准方法主要有以下四步:特征提取 → 兴趣点采样 → 特征匹配 → RANSAC(随机采样一致)
特征提取:就是给每个点一个高维度特征(一般是32维度的)
兴趣点采样:点云数据的输入可能是几十万个点,不可能用这么大的数据量去跑Feature matching或者RANSAC,这样做的内存开销太大。所以一般会取500个点 1000个点去匹配,常见有random sampling(随机采样),也有方法认为要采样边界上的点或者角点这类特殊点会比较容易匹配正确。
特征匹配:每个点找特征距离最近的点从而得到同名点对。
随机采样一致:用同名点对去解变换方程的旋转矩阵R和平移向量t,最小化同名点对在特征空间的距离。
PREDATOR总体思路
点云配准:给定两个点云 P = {pi ∈ R3|i = 1..N } ,和Q = {qi ∈ R3|i = 1..M } ,目标是找到一个刚性变换 T 使 P 和 Q 对齐。在Predator中,它的基本思路是重叠区域对于点云配准非常重要,单看一个点很难看出这个点是不是在重叠区域内,因为单个点没有重叠信息。而看一个patch(一小片)区域很容易看出是不是在重叠区域,所以关注的焦点是一小片区域,要在特征匹配时去匹配patch而部署point。
PREDATOR结构
Predator的结构主要包含Encoder、Overlap attention module和Decoder三部分。
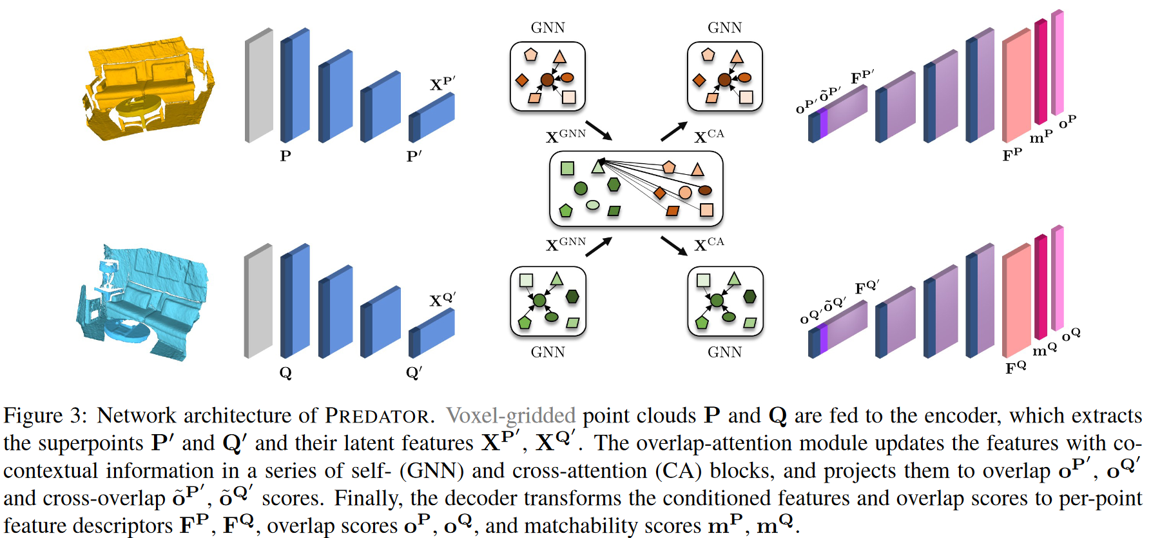
- Encoder:将点云编码为更小的集合—superpoints。认为super point是一个patch
- Overlap attention module:提取两个点云的特征之间的上下文信息,并为每个superpoint分配两个重叠分数(衡量此superpoint及其匹配点位于重叠区域的可能性)。
- Decoder:将Overlap attention module的输出解码为特征表示Fp、重叠得分Op 、匹配得分 mp。
接下来是对每个部分的详细介绍。
Encoder
Encoder部分首先使用体素网格滤波对原始点云做下采样,使得点云P Q具有合理均匀的点密度。随后又使用了一系列的ResNet-like blocks andstridedconvolutions对P Q特征提取和降采样到为一个superpoint的集合P’ Q’,Xp’ Xq’表示其对应的特征。这样每个superpoint就可以表征点云中的一个patch,或者说每个superpoint就包含了点云中的一个patch的信息。
Overlap attention module
Overlap attention module的目的是使得两个点云产生信息交互,从而找到重叠区域。主要步骤是夸大感受野 → 找到重叠区域 → 获得overlap-score,分别通过GNN Transformer和GNN实现。
Graph convolutional neural network:在两个点云进行交互产生联系之前,使用图卷积网络扩大superpoint的感受野,使其能看到更多的上下文信息,学习到局部邻域点的信息,更好地描述点云中的一个patch。
Cross-attention block:利用Transformer实现,通过对分别来自两个点云的superpoint进行两两比较,从而确定其是否位于重叠区域。如果superpoint pi′ 在 Q′ 中找到了一个与比较像的superpoint,那么 pi 可能位于重叠区域。此过程是利用Transformer来实现的,也就是用P中的点找Q中的点,并用Q中点的信息更新P中点的特征。分别对P’ Q’施加同样操作,可以实现信息流在PQ之间的交互。
Overlap scores of the bottleneck points:上一步上下文信息更新是对独立地对每一个超点进行更新的,没有考虑每片点云内部的局部上下文。因此,在cross-attention block之后用另一个GNN网络去更新了内部上下文信息。可以理解成平滑或修正孤立点(3D中如果附近的点都在重叠区域,这个点大概率也在重叠区域)。然后将特征线性投影成overlap-scores,overlap-scores可以理解为某个点位于重叠区域的概率。
Decoder
上一步得到了overlap-scores,也就是某个点位于重叠区域的概率。但是事情还没完,这个点位于重叠区域中的概率确定了,但是这个点会在Q中找到一个和它很像的点,这个点在不在overlap里面也很重要,所以也要计算和它很像的点在overlap里面的概率。只有它和它对应的点都在重叠区域内才是所需要的正确的匹配,否则并不是正确匹配的。因此Decoder里面记录了又计算了匹配分数mp,代表预测出Q 中点的overlap-score。拼接特征表示F,重叠得分o,匹配得分m就得到了Decoder的结果。
损失函数设计
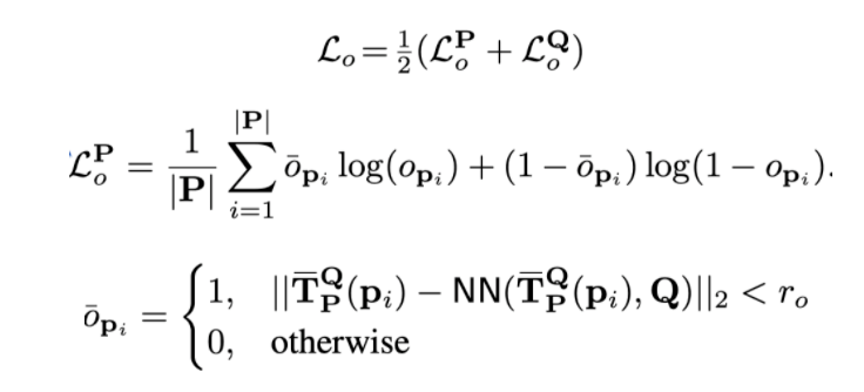
这篇文章的Loss由循环损失、重叠损失和可匹配性损失三部分组成。
循环损失
循环损失的目的可以理解成最小化类间相似度、最大化类内相似度。
通过变换矩阵对P和Q进行变换对齐,首先提取在Q中至少有一个重叠的超点pi,假设Q中距离pi小于rp的点为正对(算Σp),在这个半径之外的点为负对(Σn)。然后在P中随机采样np个超点计算循环损失。
重叠损失
重叠概率估计可以当作二分类问题。重叠损失的目的是让点是否在重叠区域内的标签预测尽可能准确。overlap loss 如果用变换矩阵T将点云P上一点pi变换到点云Q上,并在其邻域内找到一点,这两个点的距离很小,则认为pi是在重叠区域的,其label为1。
可匹配性损失
matchability loss 在特征空间上,寻找与pi 特征相近的点,用变换矩阵T将pi变换到点云Q上一点,如果这两个点的距离很小,则认为这两个点是一对匹配点,其label为1。可匹配性和重叠概率一样,也是一个二分类问题,目的是尽可能多地找到可匹配的点。
实验结果
用overlap 和 matchability score乘一下得到得分,作者比较了三种采样方法:Random、Top-k、Probablistic。
Random:随机采样,作为baseline。
Top-k:选取最好的k个点。
Probablistic:Top-k + Random, 防止采样都在一个簇里。
比较了两个指标:Inlier ration和Registration recall。
Inlier ratio:在配准过程中,成功匹配的符合要求的点对数量与总点对数量之比。
Registration recall:成功配准的点云对数与总点云对数之比。
Registration recall衡量了成功配准的点云对的数量,而 Inlier ratio 则更关注于匹配过程中点对的质量和匹配的准确性。
从结果可以看出Top-k在Inlier ratio数值更好但Probablistic在Registration recall也就是最终结果中表现更佳。推测应该是Probablistic能找到一个更大的重叠区域去做点云配准,从而得到更好的效果。
作者还做了一些其他的实验去比较Predator和其他方法,基本上都是Predator的效果比较好。但看Paper with code网站里从2022年开始应该还是有一些方法又超过了Predator的。
作者的叨叨
这篇博客大概就是这样了,不知道有没有人有耐心看到这里,这篇基本上是对整个方法思路的一个介绍,对文中涉及到的公式并没有做过多解释,有兴趣的可以去看看原文。